
로딩 중이에요... 🐣
01 결측치 탐지 | ✅ 저자: 이유정(박사)
터미널에서 패키지 설치하는 방법
pip install seaborn
pip install seaborn matplotlib
jupyter에서 패키지 설치하는 방법
!pip install seaborn
!pip install seaborn matplotlib
matplotlib 맵플롯립 라이브러리:가장 기본적인 시각화 라이브러리로 선 그래프, 막대 그래프, 산점도 등을 시각화 할수 있습니다.seaborn 시본 라이브러리:matplotlib 위에서 작동하는 고급 시각화 도구로 통계 기반 시각화, 예쁜 그래프 스타일 제공합니다.
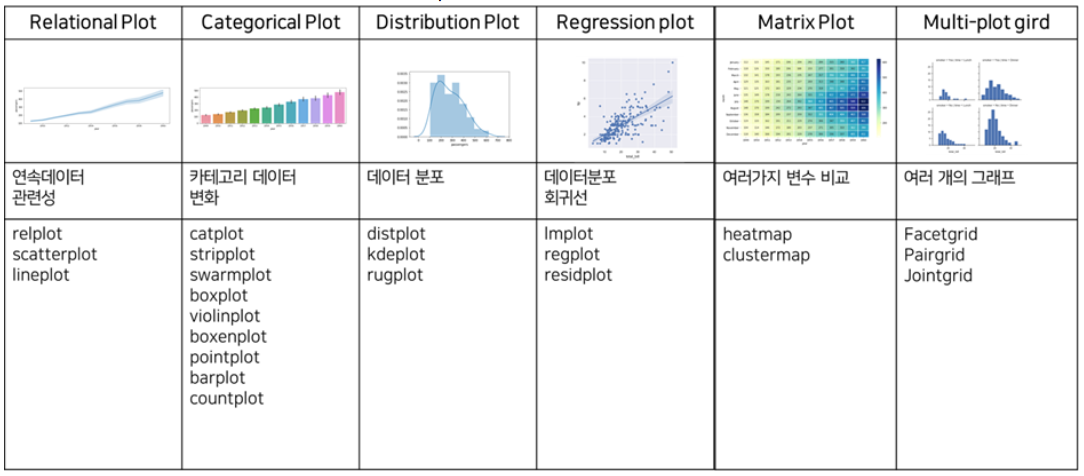
seaborn으로 할 수 있는 것들
- 히스토그램 (
sns.histplot) - 박스플롯 (
sns.boxplot) - 산점도 (
sns.scatterplot) - heatmap (
sns.heatmap) - 범주형 변수 비교 (
sns.barplot,sns.countplot) - 상관관계 시각화 (
sns.pairplot,sns.heatmap)
seaborn은 내부적으로 matplotlib을 사용합니다.
그래서matplotlib도 함께 설치되어 있어야 seaborn이 제대로 작동해요.
🧼 결측치(누락된 값) 처리란? fill + NaN 즉 결측치를 뜻하며 데이터 안에 비어있는 값(NaN)이 있을 때, 그 빈자리를 채우거나 제거하는 과정입니다. 제대로 처리하지 않으면 분석이나 머신러닝 모델이 오류를 낼 수 있어요.
결측치 처리 방법 요약:
| 방법 | 설명 |
|---|---|
fillna() |
빈 값을 어떤 값으로 채우기 |
dropna() |
빈 값이 있는 행 또는 열을 삭제 |
interpolate() |
앞뒤 값을 기준으로 자연스럽게 채우기 |
| 예측 모델 사용 | 다른 데이터로 예측해서 채우기 |
결측치는 어떤 기준으로 채워야 할까, 아니면 버려야 할까? 결측치 처리 판단 기준
| 질문 | 예/상황 | 처리 방식 |
|---|---|---|
| 결측치가 많나요? | 전체의 30% 이상이 NaN? | → 버리는 걸 고려 (dropna) |
| 해당 열이 중요해요? | 분석에 꼭 필요한 값? | → 채우기 고려 (fillna) |
| 문제가 숫자예요? 범주예요? | 나이/금액 vs 성별/지역 | → 숫자는 평균, 범주는 최빈값으로 채우기 |
| 정확성이 중요해요? | 예: 의료 데이터, 금융 | → 결측치 제거 또는 예측모델로 정교하게 채움 |
| 시간 순 데이터예요? | 시계열(날짜별) 데이터 | → 앞뒤값으로 채움 (method="ffill", bfill) |
결측치가 많고 중요하지 않다면?
df.dropna(subset=["email"])
# 이메일이 없는 행 삭제
- 이메일은 식별/연락용 → 결측이면 의미 없음
- 결측이 있다면 삭제하는 게 나음
- 이메일 없는 행은 제거됨
결측치가 적고 중요한 숫자값이라면?
df["age"].fillna(df["age"].mean(), inplace=True)
# 평균 나이로 채움
age는 중요한 숫자 데이터 (분석/분류에 필요함)- 결측치가 적고 → 채우는 것이 낫다
- 예: 평균이 28.5이면 결측치의 age도 28.5로 채워짐
결측치가 범주형(문자)이라면?
df["gender"].fillna(df["gender"].mode()[0], inplace=True)
# 가장 많이 나온 성별로 채움
gender는 범주형 데이터- 결측이 1~2개면 최빈값(F) 가장 자주 나오는 값으로 채우는 게 일반적
- 가장 많이 등장한
F로 결측값 채워짐
데이터가 시간 순서라면?
df["temperature"].fillna(method="ffill", inplace=True)
# 바로 이전 값으로 채움
- 일별 기온 측정값이 중간에 없음 (시간 순 데이터)
- 시계열 데이터 → 흐름이 중요
- 중간 결측은 이전 값 또는 선형 보간으로 채움
2024-01-02의 온도가3.1또는 평균3.55로 채워짐
📝 데이터 예시
| 날짜 | 온도 |
|---|---|
| 2024-01-01 | 3.1 |
| 2024-01-02 | NaN |
| 2024-01-03 | 4.0 |
결측치가 전체의 절반 이상일 때
예: 100명 중 60명의 income이 결측
판단:
- 너무 많은 결측 → 채워도 신뢰도 낮음
- 열 자체를 제거하거나, 예측모델 사용 고려
df.drop("income", axis=1, inplace=True)
결측치 채우기
fillna() – 비어있는 값을 채우기
df["age"].fillna(값, inplace=True)
채우는 값의 종류
| 방식 | 설명 | 예시 |
|---|---|---|
| 평균값 (mean) | 전체 평균으로 채우기 | df["age"].fillna(df["age"].mean()) |
| 중앙값 (median) | 중간 값으로 채우기 | df["age"].fillna(df["age"].median()) |
| 최빈값 (mode) | 가장 많이 나온 값으로 채우기 | df["age"].fillna(df["age"].mode()[0]) |
| 앞의 값으로 채우기 | 위에서 아래로 채움 (forward fill) | df["age"].fillna(method="ffill") |
| 뒤의 값으로 채우기 | 아래에서 위로 채움 (backward fill) | df["age"].fillna(method="bfill") |
dropna() – 결측치가 있는 행/열 삭제
df.dropna() # 결측치가 있는 행 삭제
df.dropna(axis=1) # 결측치가 있는 열 삭제
데이터가 너무 많이 빠져있을 때만 사용하는 것이 좋아요.
interpolate() – 앞뒤 값을 기준으로 자연스럽게 채우기
df["value"].interpolate()
시간 흐름이 있는 데이터나, 연속적인 숫자일 때 사용하면 자연스럽게 값이
연결돼요.
예측 모델로 결측치 채우기
머신러닝 모델을 사용해서 결측값을 예측해서 채워요.
예를 들어, age가 없는 사람들의 나이를 다른 열(email, join_date)을 이용해 예측 모델(RandomForest, LinearRegression 등)로 채울 수 있어요.
실습예제:
import pandas as pd
import numpy as np
df = pd.read_csv("csv_files/combined_customers.csv")
# 결측치 탐지
print(df.isnull()) # 각 셀별로 결측치 여부 확인
print("\n 결측치 개수:")
print(df.isnull().sum())
pd.read_csv()
- CSV 파일을 불러와서 DataFrame으로 읽어오는 메서드입니다.
- 경로에 있는
combined_customers.csv파일을 읽어와df변수에 저장해요.df.isnull() - 결측치(NaN)인지 True/False로 판별하는 메서드입니다.
- 각 셀마다 결측치면
True, 아니면False가 나와요.df.isnull().sum() - 각 열(column)별 결측치 개수를 계산하는 메서드 조합입니다.
isnull()로 찾은True값을sum()으로 세는 방식이에요.- 결과는 시리즈 형태로 "어떤 열에 몇 개의 결측치가 있는지" 보여줘요.
결과:
customer_id name age email join_date
0 False False True False False
1 False False True False False
2 False False True False False
3 False False True False False
4 False False True False False
.. ... ... ... ... ...
495 False False False False False
496 False False False False False
497 False False False False False
498 False False False False False
499 False False False False False
[500 rows x 5 columns]
결측치 개수:
customer_id 0
name 0
age 22
email 22
join_date 0
dtype: int64
결측치 시각화
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
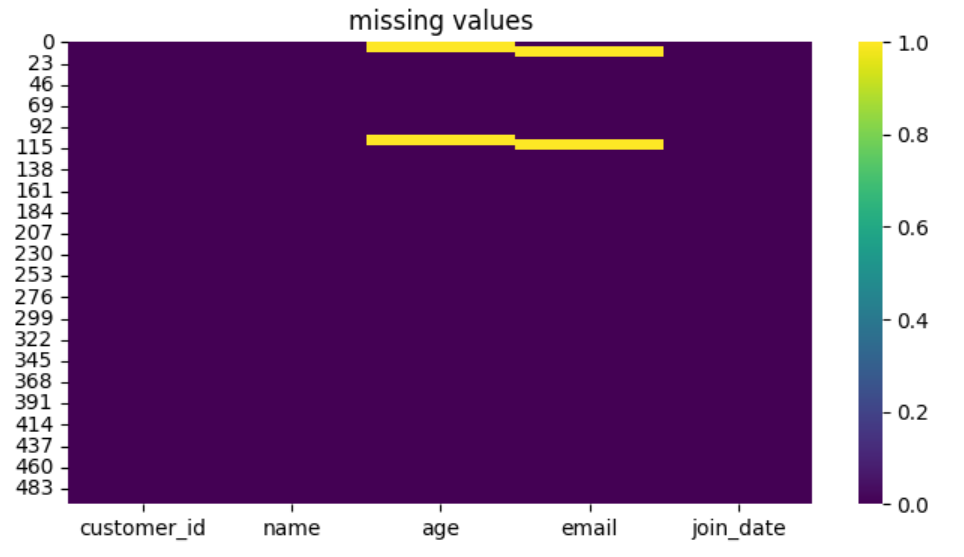
# 결측치 시각화를 위한 히트맵
df = pd.read_csv("csv_files/combined_customers.csv")
plt.figure(figsize=(8, 4))
sns.heatmap(df.isnull(), cbar=True, cmap='viridis')
plt.title('missing values')
plt.show()
print(df.isnull().sum()) # 컬럼별 결측치 개수
print(df[df.isnull().any(axis=1)]) # 결측치가 있는 행 보기
plt.figure(figsize=(8, 4))
- 시각화 그래프의 크기를 설정하는 함수
- 너비 8, 높이 4인 도화지를 설정함
sns.heatmap(data, ...) - 히트맵 형태로 데이터 시각화
- 여기선 True/False 값을 색상으로 표시해 결측치 위치 시각화
- cmap='viridis'는 색상 스타일 설정
- cbar=True는 오른쪽에 색상 범례 표시
df.isnull() - 결측치(NaN) 여부를 True/False로 표시하는 메서드
- 시각화에 사용됨 (True는 결측치!)
plt.title("제목") - 그래프의 제목을 설정하는 함수
plt.show() - 그래프를 화면에 출력하는 함수
- Jupyter 등에서 실제 시각화 결과를 보여줌
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv("csv_files/combined_customers.csv")
# 결측치 개수 계산
missing_counts = df.isnull().sum()
# 결측치가 있는 컬럼만 시각화
missing_counts = missing_counts[missing_counts > 0]
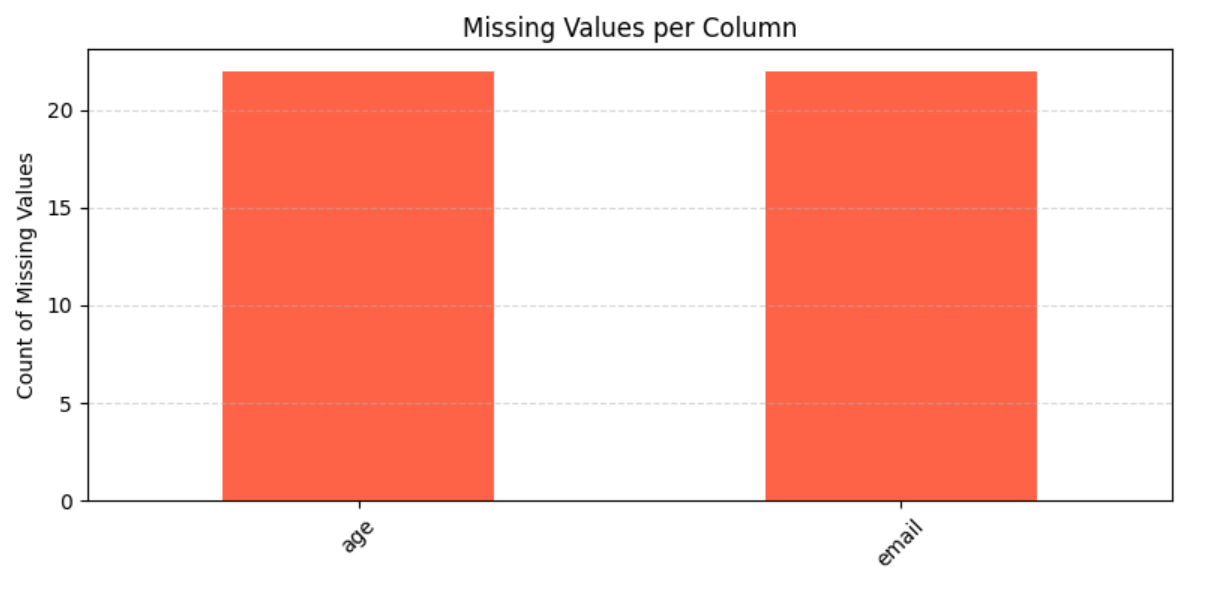
# 막대그래프
plt.figure(figsize=(8, 4))
missing_counts.plot(kind='bar', color='tomato')
plt.title('Missing Values per Column')
plt.ylabel('Count of Missing Values')
plt.xticks(rotation=45)
plt.grid(axis='y', linestyle='--', alpha=0.5)
plt.tight_layout()
plt.show()
missing_counts[missing_counts > 0]
- 결측치가 1개 이상 있는 컬럼만 필터링
plt.figure(figsize=(8, 4)) - 시각화 도화지의 크기를 설정 (가로 8, 세로 4)
missing_counts.plot(kind='bar') - 결측치 개수를 막대그래프로 그리는 메서드
kind='bar'는 막대그래프 유형,color='tomato'는 색상plt.title("...")- 그래프의 제목 설정
plt.ylabel("...") - y축 라벨 설정
plt.xticks(rotation=45) - x축 라벨(컬럼명)을 45도 회전
plt.grid(axis='y', linestyle='--', alpha=0.5) - y축 기준의 점선 그리드 추가 (투명도 50%)
plt.tight_layout() - 그래프 요소들이 겹치지 않도록 자동 정렬
plt.show() - 그래프를 화면에 출력
한글 폰트 설치 WSL은 한글을 지원하지 않고 윈도우에 있는 폰트도 불러들여 지지 않아 직접 설치
sudo apt update
sudo apt install -y fonts-nanum
# 폰트 캐시 리빌드
sudo fc-cache -fv
# 설치된 폰트 확인
fc-list | grep Nanum
예: /usr/share/fonts/truetype/nanum/NanumGothic.ttf 같은 경로가 나오면 성공
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
# 한글 폰트 경로 지정 (WSL에 설치된 Nanum Gothic 사용)
font_path = "/usr/share/fonts/truetype/nanum/NanumGothic.ttf"
font_prop = fm.FontProperties(fname=font_path)
# 데이터 불러오기
df = pd.read_csv("csv_files/combined_customers.csv")
# 결측치가 있는 행만 추출
missing_df = df[df.isnull().any(axis=1)]
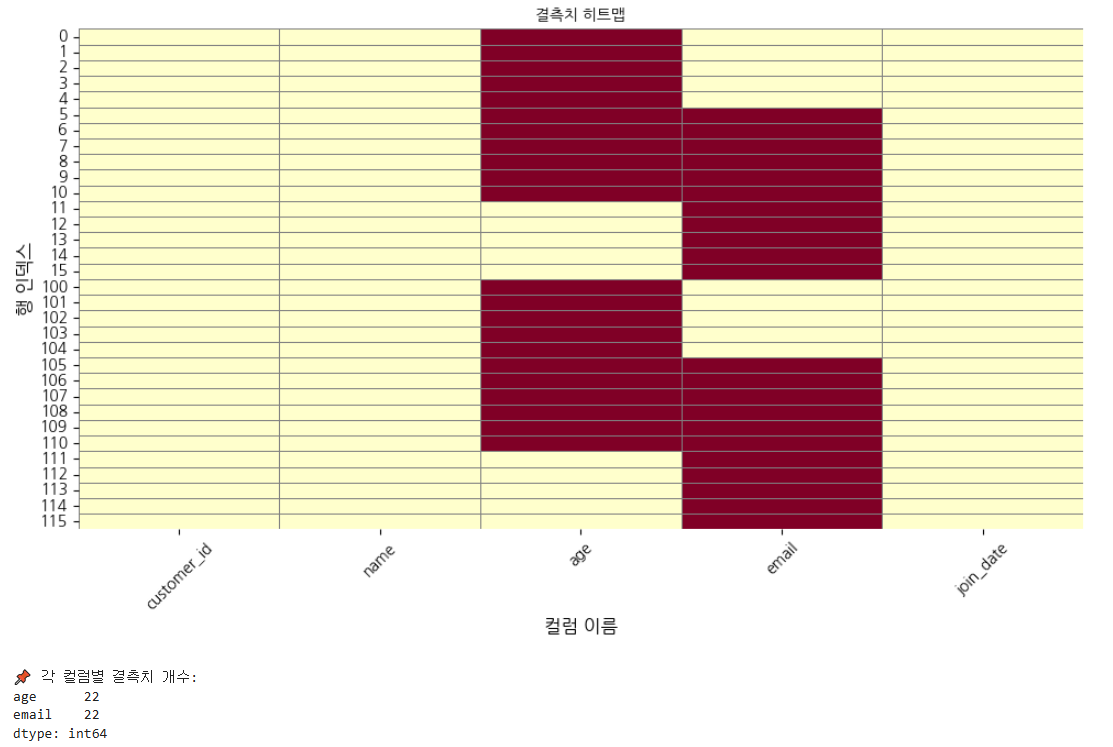
# 히트맵 시각화
plt.figure(figsize=(10, 6))
sns.heatmap(
missing_df.isnull(),
cmap="YlOrRd",
cbar=False,
linewidths=0.5,
linecolor="gray"
)
# 한글 폰트 적용 부분에서 fontproperties 사용
plt.title("결측치 히트맵", fontsize=16, fontproperties=font_prop)
plt.xlabel("컬럼 이름", fontsize=12, fontproperties=font_prop)
plt.ylabel("행 인덱스", fontsize=12, fontproperties=font_prop)
plt.xticks(rotation=45, fontproperties=font_prop)
plt.yticks(rotation=0, fontproperties=font_prop)
plt.tight_layout()
plt.show()
# 결측치 개수 출력
print("\n 각 컬럼별 결측치 개수:")
print(df.isnull().sum()[df.isnull().sum() > 0])
missing_df = df[df.isnull().any(axis=1)]
isnull()메서드: 셀 값이NaN이면True, 아니면False반환any(axis=1): 각 행(가로 방향) 기준으로 하나라도NaN이 있으면True- 전체에서 결측치가 1개 이상 포함된 행만 추출해서
missing_df로 저장
plt.figure(figsize=(10, 6))
- 새로운 그래프 영역 생성
figure()메서드: 그림 사이즈를(너비, 높이)로 지정
sns.heatmap(
missing_df.isnull(),
cmap="YlOrRd",
cbar=False,
linewidths=0.5,
linecolor="gray"
)
heatmap()메서드: 결측치(누락값)를 시각적으로 보여주는 히트맵 생성isnull()로 결측치 여부만True/False로 표시cmap="YlOrRd": 색상 테마 (노랑-오렌지-빨강 계열)cbar=False: 오른쪽 컬러바 안 보이게 설정linewidths=0.5,linecolor='gray': 셀 경계선 추가
plt.title("결측치 히트맵", fontsize=16, fontproperties=font_prop)
- 그래프 제목 설정
fontsize=16: 글자 크기fontproperties=font_prop: 위에서 만든 한글 폰트 적용
plt.xlabel("컬럼 이름", fontsize=12, fontproperties=font_prop)
plt.ylabel("행 인덱스", fontsize=12, fontproperties=font_prop)
- x축과 y축 라벨 지정
- 마찬가지로 한글 폰트와 크기 설정 포함
plt.xticks(rotation=45, fontproperties=font_prop)
plt.yticks(rotation=0, fontproperties=font_prop)
xticks(),yticks(): 눈금 글자 회전 및 폰트 적용- x축은 45도 기울이고, y축은 0도 (수직)으로 유지
plt.tight_layout()
- 그래프 요소들이 겹치지 않도록 자동 정렬
- 글자가 잘림 없이 보여지게 함
plt.show()
- 그래프 창 띄우기
- 지금까지 설정한 시각화를 출력
print(df.isnull().sum()[df.isnull().sum() > 0])
isnull()→ 결측치 여부를True/False로 반환sum()→ 컬럼 단위로True개수 합산 = 결측치 개수[ > 0 ]→ 결측치가 1개 이상 있는 컬럼만 출력
결측치 처리
평균값으로 결측치 채우기 (Mean Imputation)
age컬럼의 평균값을 계산해서, 비어 있는 셀(NaN)에 채워 넣습니다.- 데이터가 대체로 정규분포(종모양)일 때 적절함.
import pandas as pd
df = pd.read_csv("csv_files/combined_customers.csv")
df['age'].fillna(df["age"].mean(), inplace=True)
print(df)
df["age"].mean()
age컬럼의 평균값을 계산합니다. 예를 들어:
age = [25, NaN, 30]
평균 = (25 + 30) / 2 = 27.5
df['age'].fillna(..., inplace=True)
NaN(결측치)을 평균값으로 채웁니다.inplace=True: 기존 데이터프레임df자체를 수정합니다. 즉, 결측치가 평균값으로 대체됨.
print(df)
- 수정된 데이터프레임을 출력합니다.
결측치(NaN)가 있던 age 값이 평균값으로 채워졌습니다.
이 방법은 수치형 데이터에서 자주 사용되며, 데이터 손실 없이 분석을 이어갈 수 있습니다.
중앙값으로 결측치 채우기 (Median Imputation)
age컬럼의 중앙값(중간에 있는 값)으로 결측치를 대체합니다.- 극단적인 값(이상치)의 영향을 줄이기 위해 사용됩니다.
import pandas as pd
df = pd.read_csv("csv_files/combined_customers.csv")
df['age'].fillna(df["age"].median(), inplace=True)
print(df)
df["age"]
- 데이터프레임
df에서age컬럼만 선택합니다.
df["age"].median()
age컬럼의 중앙값(중간값, median) 을 구합니다.- 중앙값이란:
- 데이터를 크기 순으로 정렬했을 때, 가운데에 위치한 값
- 예:
[22, 24, 27, 30, 32]→ 중앙값은27[20, 25, NaN, 30, 35]→ NaN 제외하고[20, 25, 30, 35]→ 중앙값은(25+30)/2 = 27.5
fillna(..., inplace=True)
NaN값을 지정된 값(여기서는 중앙값)으로 채웁니다.inplace=True:- 원본 데이터프레임(
df)을 직접 수정합니다. - 새로 저장하지 않아도 즉시 반영됨
- 원본 데이터프레임(
최빈값(데이터에서 가장 자주 나오는 값)으로 결측치 채우기 (Mode Imputation)
age컬럼에서 가장 자주 등장하는 값을 찾아서 결측치를 채웁니다.- 범주형 또는 반복이 많은 숫자형 데이터에 적합.
import pandas as pd
df = pd.read_csv("csv_files/combined_customers.csv")
print(df["age"].mode())
df['age'].fillna(df["age"].mode()[0], inplace=True)
print(df)
print(df["age"].mode())
df["age"]: age 컬럼 선택.mode()
→ 최빈값(가장 자주 등장한 값)을 구하는 메서드
→ 반환값은 Series 형태이고, 최빈값이 여러 개일 수도 있어서 리스트처럼 생김
[20, 22, 22, 23, 25, 25, 25, 30]
→ mode() 결과: [25] (25가 가장 많이 나옴)
[20, 22, 22, 25, 25]
→ mode() 결과: [22, 25] (22와 25가 둘 다 2번 등장, 공동 최빈값)
df['age'].fillna(df["age"].mode()[0], inplace=True)
df["age"].mode()[0]
→ 최빈값 중 첫 번째 값 (가장 많이 등장한 나이 하나를 가져옴)fillna(..., inplace=True)
→NaN값을 해당 최빈값으로 직접 대체
→inplace=True: 원본 데이터df를 바로 수정
예를 들어, age가 아래와 같다고 해볼게요:
| name | age |
|---|---|
| Alice | 25 |
| Bob | NaN |
| Charlie | 30 |
| David | 25 |
| Ellen | NaN |
→ .mode() 결과는 [25]
→ fillna(25)
→ NaN이 25로 바뀜
| name | age |
|---|---|
| Alice | 25 |
| Bob | 25 |
| Charlie | 30 |
| David | 25 |
| Ellen | 25 |
print(df)
- 바뀐 전체 데이터프레임을 출력합니다.
- NaN이 최빈값으로 채워졌는지 확인할 수 있음
바로 앞 값으로 채우기 (Forward Fill / ffill)
- 결측치가 있을 경우 그 위(이전 행)의 값으로 채워줍니다.
- 시계열 데이터나 순서가 중요한 경우에 유용합니다.
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# 결측치 시각화를 위한 히트맵
df = pd.read_csv("csv_files/combined_customers.csv")
df['age'].fillna(method="ffill",inplace=True)
plt.figure(figsize=(8, 4))
sns.heatmap(df.isnull(), cbar=True, cmap='viridis')
plt.title('missing values')
plt.show()
df['age'].fillna(method="ffill", inplace=True)
df['age']:age라는 열(나이 컬럼)을 선택합니다..fillna(...): 결측치(NaN)를 채우는 함수입니다.method="ffill": 앞에 있는 값으로 채워라는 뜻 (forward fill).inplace=True: 원본 데이터프레임df를 직접 수정합니다.
age = [25, NaN, NaN, 30] → forward fill 후: [25, 25, 25, 30]
- 시간순 데이터나 설문 응답 등에서 이전 값을 유지하는 게 더 자연스러울 때 사용
plt.figure(figsize=(8, 4))
- 새로운 그래프 영역을 만듭니다.
figsize=(8, 4)는 가로 8인치, 세로 4인치로 크기를 설정합니다.
sns.heatmap(df.isnull(), cbar=True, cmap='viridis')
df.isnull():NaN인지 여부를True/False로 바꾼 데이터프레임을 만듭니다.sns.heatmap(...): 결측치를 시각화하는 히트맵(열 지도)을 그립니다.cbar=True: 오른쪽에 색상 범례를 표시합니다.cmap='viridis': 색상 테마를viridis로 설정 → 밝은 색은 결측치, 어두운 색은 정상값
plt.title('missing values')
- 그래프의 제목을 'missing values'로 설정합니다.
plt.show()
- 지금까지 설정한 그래프를 실제로 화면에 보여줍니다.
보간법(interpolation)으로 채우기 (선형 보간)
- 앞뒤 값의 중간값을 계산해서 결측치를 채웁니다.
- 숫자형 연속 데이터에서 경향성을 유지하며 채우고 싶을 때 적합합니다.
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# 결측치 시각화를 위한 히트맵
df = pd.read_csv("csv_files/combined_customers.csv")
df['age'].interpolate(inplace=True)
plt.figure(figsize=(8, 4))
sns.heatmap(df.isnull(), cbar=True, cmap='viridis')
plt.title('missing values')
plt.show()
df['age'].interpolate(inplace=True)
df['age']:age(나이) 컬럼만 선택합니다..interpolate(): 결측치(NaN)를 앞뒤 숫자들 사이의 값으로 채워주는 함수입니다. 즉, 선형 보간(linear interpolation) 방식입니다.inplace=True: 원본df데이터프레임을 직접 수정합니다.
예시:
age = [20, NaN, 40]
→ interpolate() 후: [20, 30, 40] ← 20과 40 사이의 중간값(30)으로 채움
보간(interpolation)은 수학적으로 연속된 수치를 예측할 때 사용합니다.
plt.figure(figsize=(8, 4))
- 그래프 영역을 새로 만듭니다.
figsize=(8, 4)는 가로 8인치, 세로 4인치의 크기를 지정합니다.
sns.heatmap(df.isnull(), cbar=True, cmap='viridis')
df.isnull(): 결측치 여부를True/False로 표시한 데이터프레임을 생성합니다.sns.heatmap(...): 이 정보를 시각적으로 보여주는 히트맵을 생성합니다.cbar=True: 오른쪽에 색상 범례(color bar)를 추가합니다.cmap='viridis': 컬러맵을viridis스타일로 지정 (색상 대비가 뚜렷함)
🟨 밝은색: 결측치 있음 (True)
🟩 어두운색: 결측치 없음 (False)
plt.title('missing values')
- 히트맵 그래프의 제목을
'missing values'로 설정합니다.
plt.show()
- 지금까지 설정한 그래프를 화면에 출력합니다.